고정 헤더 영역
상세 컨텐츠
본문
https://www.youtube.com/watch?v=wYgyiCEkwC8&list=PLpRS2w0xWHTcTZyyX8LMmtbcMXpd3s4TU
본 필기노트는 위 영상을 바탕으로 합니다.
머신러닝은 3가지 종류로 나뉜다.

1. Unsupervised Learning - 비지도 학습
2. Supervised Learning - 지도 학습
3. Reinforcement Learning - 강화학습
■ 강화학습이 기존의 다른 머신러닝 방법론과 차이를 가지는 점
● Supervisor가 존재하지 않으며, reward signal만이 존재함.
- Supervised Learning과의 차이점
정답을 알려주지 않고 reward signal만으로 좋은 방향을 찾아나간다.
어떤 방향, 어떤 방법을 사용해야 reward를 많이 받는지(Supervisor의 역할)는 알려주지 않는다.
다만 reward를 Maximaize하는 방법을 스스로 찾아나갈 뿐.
장점 : 인간이 생각하는 것 이상으로 넘어설 수 있다. (ex- 알파고)
● Feedback(reward)가 Delay될 수 있다.
- Supervised Learning과의 차이점.
지도학습(Supervised Learning)은 예를 들어 개나 고양이 사진을 분류하는 과정에서 Supervisor가 정답을 뒤늦게 알려주는 경우는 없다. 하지만 Reinforcement Learning에서는 Reward가 Delay될 수 있다. 이게 어려운 점이다.
● Time really matters 시간이 굉장히 중요하다.
- 강화학습은 Sequential한 data를 다룬다. 순서가 중요하다. 각각 독립적인 데이터를 다루지 않는다.
● Agent의 action이 subsequent(후속) data에 영향을 준다.
- Agent가 어떻게 fitting하느냐에 따라서 후속 data에 계속해서 영향을 준다.
알파고를 생각하면 될 것 같다. 바둑판은 한정되어 있고, 이번 선택이 항상 다음번 선택에게 영향을 주니까.
■ 강화학습의 예시
- 보드게임
- 주식 투자 포트폴리오 (계속해서 결정을 내리면서 Sequential하게 받으니까, reward는 이윤)
- Humanoid 로봇이 잘 걷게 (잘 걸으면 +1, 아니면 -1)
■ 용어 바로잡기
● Reward
scalar feedback signal이다. 이게 무슨 소리냐 -> 어떠한 수 하나이다.
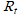
로 Reward를 표시한다. t번째 time에 Rt 만큼의 보상이 주어진다 는 뜻.
Agent의 목적은 Cumulative(누적의) reward를 Maximise한다. 단 하나의 Rt가 아니라.
Reward를 Scala feedback signal로 가져갈 수 있는 문제가 강화학습에 적합하다.
● Agent
- 우리가 학습시키는 bot
● Environment
Agent를 둘러싸고 있는 모든 것. Agent에게 Action에 대한 Reward를 제공해 주고, 그에 따른 변화를 Observation으로 제공

● History
말 그대로 History. 무슨 history냐

Observation, Reward, Action의 History다.
agent는 History를 보고 action을 정하고, Environment는 history를 보고 Observation과 Reward를 agent에 보내준다.
● State

다음에 무엇을 할지 결정하기 위해 쓰이는 정보. history 안에 있는 정보를 가공해서 State를 만든다.
그래서 State는 Histroy의 함수라고 볼 수 있다.
굉장히 중요하다!!

Environment state : Environment의 State
- Environment가 observation과 reward를 agent에게 제공하는데,
이때 사용한 state를 Environment State라고 한다.
Environment state는 agent에게는 보통 보이지 않는다.
- 게임을 할 때 화면을 보는 거지 게임 프로그램 내부에 변수의 값이나 오브젝트의 상태나 이런 걸 보지 않는 것과 같다.
↑ 여기선 우리가 agent, 게임기(Input, output 장치 포함)가 environment가 되겠죠

Agent State : Agent의 State
- Agent가 다음 action을 할 때, history에서 내가 필요한 정보들 = 사용한 state를 Agent State라고 한다.
■ Sequential Decision Making(순차적인 결정 내리기?)
- 목표 : 미래에 받을 총합의 reward를 극대화하는 것.
- Action에 대한 Consequences(결과)는 아주 나중에 정해질 수 있고, Reward 역시 Delay될 수 있다.
- immediate reward(즉각적인 보상)을 sacrifice(희생)하고 Long-term reward를 받는 게 나을 수 있다는 것.
■ Markov State 마르코프 스테이트 (Information State, 인포메이션 스테이트)

어떤 State가 Markov 한 지 안 한 지.
State가 Markov하다 = 결정 시에 이전 tick의 State만을 참고한다. 바로 이전 tick의 state에만 의존하여 결정한다.
Environment State는 항상 Markov하다.
History도 항상 Markov하다.
Agent State에서 Markov하지 않은 예시를 생각하면...
차가 있는 위치, 현재 시간, 핸들의 방향 이 3가지가 Agent State일때,
여기서 엑셀을 풀로 밟으면 다음 틱에 차의 속도를 알 수 있는가...? 없다. 때문에 Markov 하지 않다.
그 전 틱을 참고해서 차의 위치값을 통해 속도를 구해야지 다음 tick의 속도를 알 수 있다.
일단은 그렇다.
■ 예시

Agent State를 마지막 3개의 item으로 둔다면, agent는 감전을 reward로 생각할 것이고,
불, 벨, 레버의 개수로 본다면, agent는 치즈를 생각할 것이다.
이 sequence 전체로 본다면, 알 수 없다.
■ Fully Observable Environments

obserservation이 Agent State와 Environment State와 같다.
이런 경우에는 Markov Decision Process(MDP)라고 함,
■ Partially Observable Environments
Agent State가 Environment State와 같지 않은 것. EX) 로봇이 카메라를 통해 부분을 관측하는 경우.
뭐 보통 이런 경우겠지.
Partially Observable Markov Decision Process(POMDP)라고 한다.
■ RL Agent의 3가지 구성요소
- Policy
- Value
- Model
세 가지를 다 가지고 있을 수도 있고, 한 가지만 가지고 있을 수도 있다.
● Policy
- Agent의 behaviour(행동)을 규정해 준다.
- State와 Action의 Mapping. State를 넣으면 Action을 뱉어준다.
- policy는 보통 π로 표현하며, 두 가지 종류가 있다.
1. Deterministic Policy

이 경우에는 state를 넣으면 action 하나가 Deterministic 하게 정해진다.
2. Stochastic Policy

이 경우에는 state를 넣으면 여러 action의 각 action별 확률을 짚어준다.
● Value Function
상황이 얼마나 좋은지를 나타냄.
미래에 받을 수 있는 reward의 합산을 예측해서 알려준다.

내가 π라는 policy를 따라갔을 때, 미래에 얻을 수 있는 총 reward의 기댓값을 Value Function이라 한다.
위 식에서 γ는 미래 reward는 불확실하기에 조금씩 작게 예측하기 위해 0.9, 0.8 이런 값을 곱해주는 것이다.
● Model
Environment가 어떻게 될지 예측한다. → Model은 예측하기에 perfect하지 않을 수 있다는 거지.

Model이 예측하는 것은 두 가지.
1. 다음 State에 대한 예측
2. 다음 reward에 대한 예측
Model이 있으면 Model Based Agent
Model이 없으면 Model Free Agent
■ Categorizing RL agents (RL agent 분류)


■ Learning and Planning
● Reinforcement Learning
Reinforcement Learning 안에 Reinforcement Learning...? 아무튼 세부적으로 나눌 수 있다.
Learning은 Environment를 모르는 상황에서 Environment와 interaction을 통해 policy를 발전시켜 나가는 것.
● Planning
Environment를 아는 경우.
그렇다면 reward도 알고 Transition(State의 변화?)도 알고 있다.
Agent는 실제로 Environment와의 상호작용 없이도 Environment의 여기저기를 보면서 policy를 개선시킨다.
■ Exploration and Exploitation

● Exploration
: 정보를 모으는 것
● Exploitation
: 모아진 정보를 통해서 reward를 Maximize하는 것.
■ Prediction and Control
● Prediction
- 평가하는 것. Policy가 주어졌을 때 평가하는 것. → Value Function을 학습시키는 문제
● Control
- Best Policy를 찾는 문제.
참고 :
https://www.davidsilver.uk/teaching/
Teaching - David Silver
www.davidsilver.uk
교수님,,,, 정말,,, 정말,,, 어떻게 공부하지,,,
'Study > 강화학습' 카테고리의 다른 글
| 강화학습 필기노트 - 4 상태 가치 함수 V, 행동 가치 함수 Q, 벨만 방정식 Bellman equation (0) | 2023.01.12 |
|---|---|
| 강화학습 필기노트 - 3 Markov Decision Process (MDP) && Policy (0) | 2023.01.10 |
| 강화학습 필기노트 - 2 Q-learning (0) | 2023.01.10 |





댓글 영역